
Solr管理索引库
添加/更新文档
批量导入数据
使用dataimport插件批量导入数据。如果collection1下没有lib 需要自己创建一个。
第一步:把dataimport插件依赖的jar包(dist文件夹中)添加到solrcore(collection1\lib)中
第二步,将mysql的数据库驱动,将其添加到(collection1\lib)
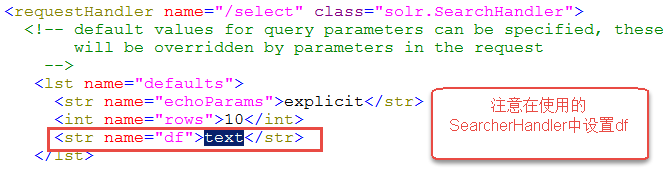
第三步:配置collection1\conf\下的solrconfig.xml文件,添加一个requestHandler。
data-config.xml
第四步:创建一个data-config.xml,保存到collection1\conf\目录下
第四步:重启tomcat
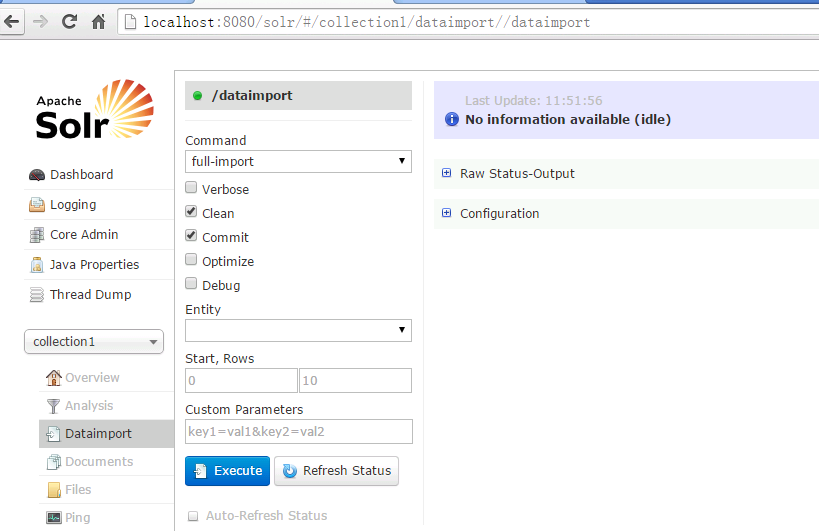
第五步:点击“execute”按钮导入数据
导入数据前会先清空索引库,然后再导入。
删除文档
删除索引格式如下:
1) 删除制定ID的索引
<delete>
<id>8</id>
</delete>
需要加上
<commit />
2) 删除查询到的索引数据
<delete>
<query>product_catalog_name:幽默杂货</query>
</delete>
<commit />
3) 删除所有索引数据
<delete>
<query>*:*</query>
</delete>
<commit />
查询索引
通过/select搜索索引,Solr制定一些参数完成不同需求的搜索:
q - 查询字符串,必须的,如果查询所有使用*:*。

fq - (filter query)过虑查询,作用:在q查询符合结果中同时是fq查询符合的,例如:

过滤查询价格从1到20的记录。
也可以在“q”查询条件中使用product_price:[1 TO 20],如下:
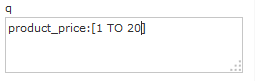
也可以使用“*”表示无限,例如:
20以上:product_price:[20 TO *]
20以下:product_price:[* TO 20]
sort - 排序,格式:sort=<field name>+<desc|asc>[,<field name>+<desc|asc>]… 。示例:
![]() 按价格降序
按价格降序
start - 分页显示使用,开始记录下标,从0开始
rows - 指定返回结果最多有多少条记录,配合start来实现分页。
 显示前10条。
显示前10条。
fl - 指定返回那些字段内容,用逗号或空格分隔多个。
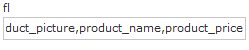 显示商品图片、商品名称、商品价格
显示商品图片、商品名称、商品价格
df-指定一个搜索Field
![]()
也可以在SolrCore目录 中conf/solrconfig.xml文件中指定默认搜索Field,指定后就可以直接在“q”查询条件中输入关键字。
、
wt - (writer type)指定输出格式,可以有 xml, json, php, phps, 后面 solr 1.3增加的,要用通知我们,因为默认没有打开。
hl 是否高亮 ,设置高亮Field,设置格式前缀和后缀。
使用SolrJ管理索引库
什么是solrJ
solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务
依赖的jar包
依赖solrj及solrj依赖包
以及lib下的扩展依赖包
使用solrj添加文档
实现步骤
第一步:创建一个java工程
第二步:导入jar包。包括solrJ的jar包,依赖包,扩展包(如上图所示)
第三步:和Solr服务器建立连接。HttpSolrServer对象建立连接。
第四步:创建一个SolrInputDocument对象,然后添加域。
第五步:将SolrInputDocument添加到索引库。
第六步:提交。
//向索引库中添加索引 @Test public void addDocument() throws Exception { //和solr服务器创建连接 //参数:solr服务器的地址 SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr"); //创建一个文档对象 SolrInputDocument document = new SolrInputDocument(); //向文档中添加域 //第一个参数:域的名称,域的名称必须是在schema.xml中定义的 //第二个参数:域的值 document.addField("id", "c0001"); document.addField("title_ik", "使用solrJ添加的文档"); document.addField("product_name", "商品名称"); //把document对象添加到索引库中 solrServer.add(document); //提交修改 solrServer.commit(); } 删除文档
//删除文档,根据id删除 @Test public void deleteDocumentByid() throws Exception { //创建连接 SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr"); //根据id删除文档 solrServer.deleteById("c0001"); //提交修改 solrServer.commit(); } //根据查询条件删除文档 @Test public void deleteDocumentByQuery() throws Exception { //创建连接 SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr"); //根据查询条件删除文档 solrServer.deleteByQuery("*:*"); //提交修改 solrServer.commit(); } 修改文档
在solrJ中修改没有对应的update方法,只有add方法,只需要添加一条新的文档,和被修改的文档id一致就可以修改了。本质上就是先删除后添加。
查询文档
简单查询
//查询索引 @Test public void queryIndex() throws Exception { //创建连接 SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr"); //创建一个query对象 SolrQuery query = new SolrQuery(); //设置查询条件 query.setQuery("*:*"); //执行查询 QueryResponse queryResponse = solrServer.query(query); //取查询结果 SolrDocumentList solrDocumentList = queryResponse.getResults(); //共查询到商品数量 System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound()); //遍历查询的结果 for (SolrDocument solrDocument : solrDocumentList) { System.out.println(solrDocument.get("id")); System.out.println(solrDocument.get("product_name")); System.out.println(solrDocument.get("product_price")); System.out.println(solrDocument.get("product_catalog_name")); System.out.println(solrDocument.get("product_picture")); } } 复杂查询
//复杂查询索引 @Test public void queryIndex2() throws Exception { //创建连接 SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr"); //创建一个query对象 SolrQuery query = new SolrQuery(); //设置查询条件 query.setQuery("钻石"); //过滤条件 query.setFilterQueries("product_catalog_name:幽默杂货"); //排序条件 query.setSort("product_price", ORDER.asc); //分页处理 query.setStart(0); query.setRows(10); //结果中域的列表 query.setFields("id","product_name","product_price","product_catalog_name","product_picture"); //设置默认搜索域 query.set("df", "product_keywords"); //高亮显示 query.setHighlight(true); //高亮显示的域 query.addHighlightField("product_name"); //高亮显示的前缀 query.setHighlightSimplePre(""); //高亮显示的后缀 query.setHighlightSimplePost(""); //执行查询 QueryResponse queryResponse = solrServer.query(query); //取查询结果 SolrDocumentList solrDocumentList = queryResponse.getResults(); //共查询到商品数量 System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound()); //遍历查询的结果 for (SolrDocument solrDocument : solrDocumentList) { System.out.println(solrDocument.get("id")); //取高亮显示 String productName = ""; Map >> highlighting = queryResponse.getHighlighting(); List list = highlighting.get(solrDocument.get("id")).get("product_name"); //判断是否有高亮内容 if (null != list) { productName = list.get(0); } else { productName = (String) solrDocument.get("product_name"); } System.out.println(productName); System.out.println(solrDocument.get("product_price")); System.out.println(solrDocument.get("product_catalog_name")); System.out.println(solrDocument.get("product_picture")); } } SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用zookeeper作为集群的配置信息中心。
它有几个特色,优点:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
SolrCloud结构
SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud需要由多台服务器组成,由Zookeeper来进行协调管理。
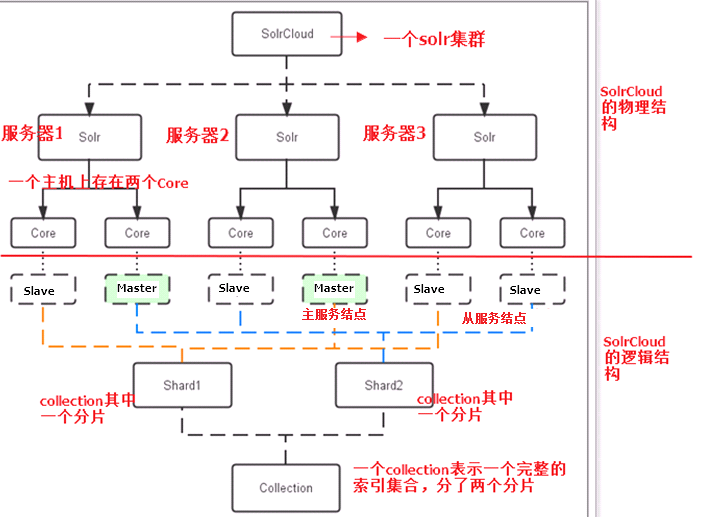
物理结构
三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud。
逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
collection
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+....+shardX
Shard
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
Core
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
Master或Slave
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。